Align-Pro: A Principled Approach to Prompt Optimization for LLM Alignment, AAAI 2024
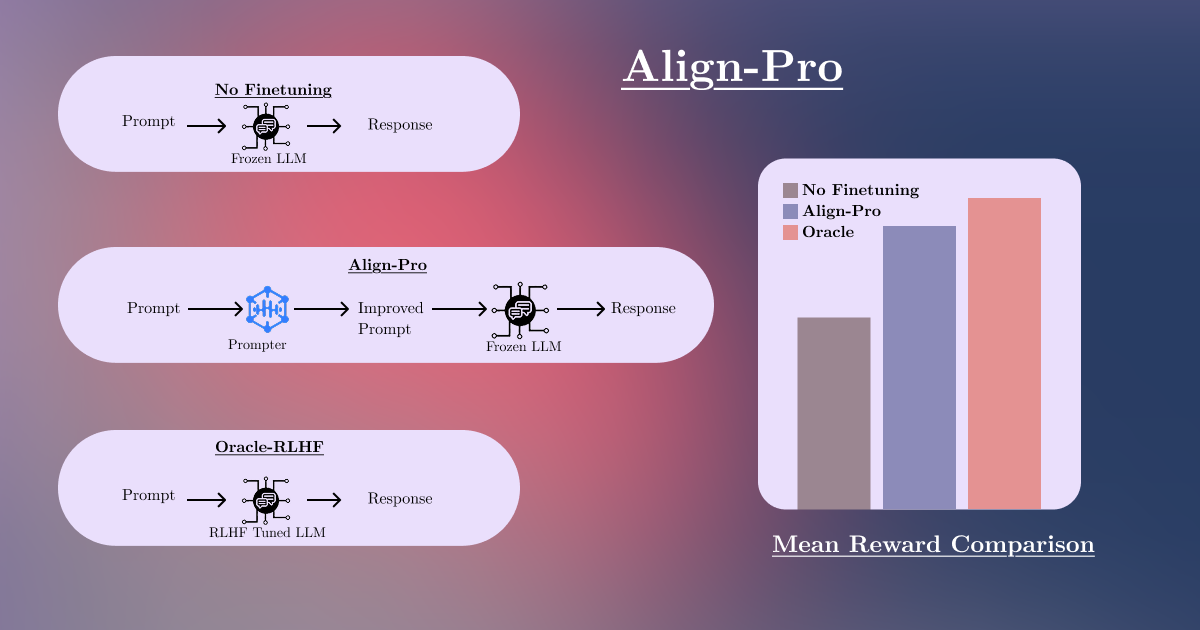
Introduction
With the rise of powerful Large Language Models (LLMs), aligning these models with human preferences and goals is both a pressing challenge and a crucial safety concern. While fine-tuning has been the standard route for alignment—especially using techniques like Reinforcement Learning from Human Feedback (RLHF)—it requires direct access to model weights and can be expensive or infeasible for closed-source or frozen models.
Align-Pro offers a compelling alternative: a prompt optimization framework that enables alignment without touching the model parameters. This blog post summarizes the core ideas, mathematical foundations, and key results behind Align-Pro.
Why Prompt Optimization?
Prompt optimization is gaining popularity as a lightweight and model-agnostic alternative to full-scale fine-tuning. But a critical question remains:
Can prompt optimization match or even approach the performance of fine-tuned models?
Align-Pro is designed to answer this question both theoretically and empirically.
Problem Setup
Assume we have:
- A frozen LLM policy
- A prompt transformer (or prompter) that modifies inputs before feeding them into
- A reward function indicating how well response aligns with desired behavior for input
The goal is to find a prompter that maximizes the expected reward under the induced policy:
Optimization Objective
Align-Pro formulates prompt optimization as the following objective:
- The first term maximizes alignment reward.
- The second KL regularization term ensures the prompter doesn’t drift too far from a reference (e.g., initial prompt distribution).
Theoretical Guarantee
Align-Pro provides a performance bound comparing the optimal fine-tuned policy and the prompt-induced policy :
This bound quantifies the sub-optimality gap and gives confidence in how close the optimized prompts come to full fine-tuning.
Closed-Form Optimal Prompt
Align-Pro also provides a closed-form for the optimal :
where:
This mirrors principles in maximum entropy RL, providing an elegant, interpretable solution.
Experimental Results
To evaluate Align-Pro, we ran experiments across 4 model architectures and 3 datasets, comparing:
- No finetuning (baseline)
- Align-Pro
- RLHF
Metrics: Mean reward and reward variance
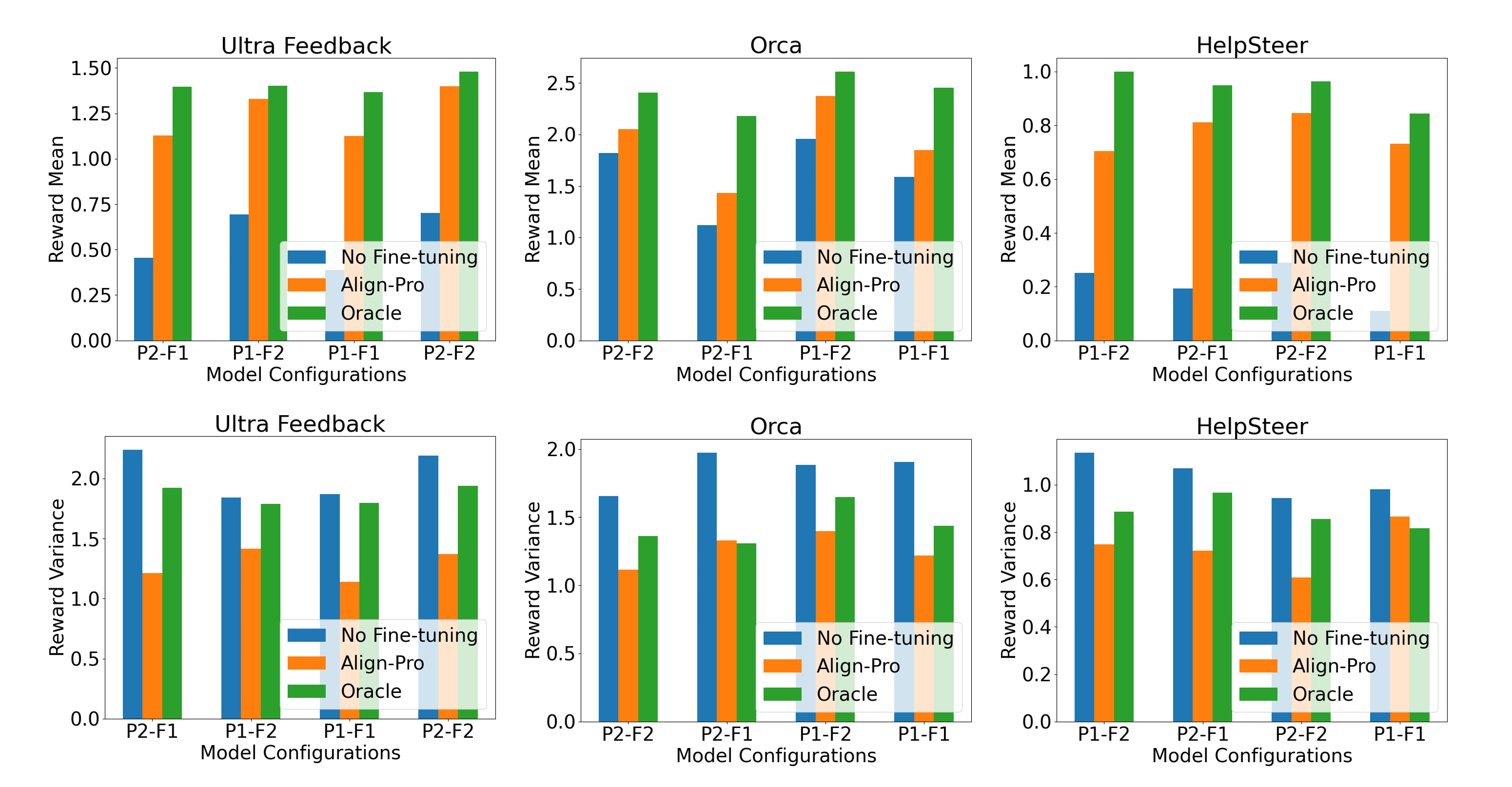
Key Takeaways:
- Align-Pro improves over the no-finetuning baseline consistently in average reward.
- RLHF slightly outperforms Align-Pro in mean reward, as expected with full access to model parameters.
- Align-Pro has lower variance, offering more stable and predictable behavior.
We also used GPT-4 as a judge to compare win rates, further validating Align-Pro’s practical effectiveness.
Conclusion
Align-Pro demonstrates that principled prompt optimization can rival the performance of parameter-based fine-tuning methods in LLM alignment tasks—without modifying the underlying model. It offers a powerful toolkit for safe, controlled alignment, especially when working with closed-source or deployment-constrained LLMs.
For researchers and practitioners working at the intersection of alignment, reinforcement learning, and prompt engineering, Align-Pro offers both theory-backed guarantees and empirical validation.
Stay tuned for more updates as we extend Align-Pro to real-world interactive settings and test generalization across tasks and domains.